Wondering what will happen to DBA community in 2020? Well they will still be around! however they will be doing cool stuff then ever before! Want to know what and how? please read...
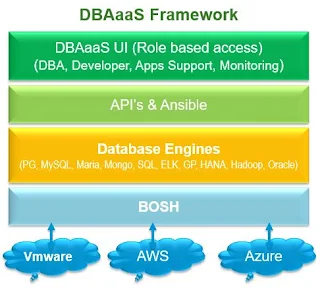
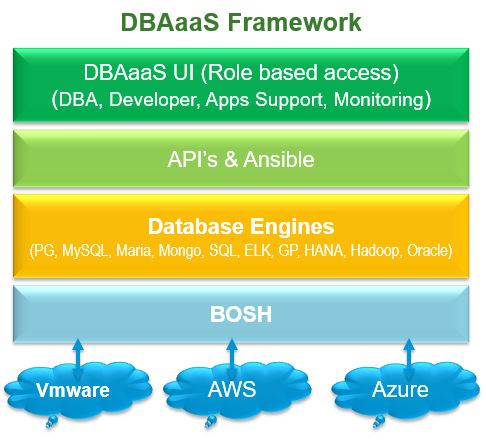
By 2020, 50%+ of all Enterprise Data will be managed Autonomously and 80%+ of Application and Infrastructure Operations will be resolved Autonomously. Well this is quite possible with AI becoming reality and cementing it's foot in the industry. To move towards this direction, first of all we need to automate all the DBA tasks, and then later on implement Machine Learning so that database will take it's own decision based on what is going on in database without any / minimal involvement of DBA's. To automate all of those tasks, we need to develop framework which I call it as DBAaaS, define roles based access, and develop a DBAaaS Mobile App / Portal!

Here is quick Prototype of "DBAaaS 1.0" Mobile App developed by me in less than 2 hours using Rapid Prototype Development tool!
URL : https://gonative.io/share/rzydnx
User name : testing
Password : test
By 2020, 50%+ of all Enterprise Data will be managed Autonomously and 80%+ of Application and Infrastructure Operations will be resolved Autonomously. Well this is quite possible with AI becoming reality and cementing it's foot in the industry. To move towards this direction, first of all we need to automate all the DBA tasks, and then later on implement Machine Learning so that database will take it's own decision based on what is going on in database without any / minimal involvement of DBA's. To automate all of those tasks, we need to develop framework which I call it as DBAaaS, define roles based access, and develop a DBAaaS Mobile App / Portal!

Here is quick Prototype of "DBAaaS 1.0" Mobile App developed by me in less than 2 hours using Rapid Prototype Development tool!
URL : https://gonative.io/share/rzydnx
User name : testing
Password : test













